
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- R 키워드 가중치
- 상호작용디자인
- 마르코프 체인
- 자언어처리모델
- R에서의 wordcloud
- 체험디자인
- R TF-IDF
- R 워드클라우드
- word2vec
- selfattention
- r word2vec
- HashMap
- 통계기반자연어처리
- self-attention
- StringBuffer vs StringBuilder
- R에서의 워드클라우드
- WordCloud R
- deeplearning용어
- StringJoiner
- 마르코프
- 언어모델
- wordVector
- R dataframe
- 자연어처리
- 딥러닝용어
- 딥러닝개념
- 도날드노만
- 어탠션
- deeplearning개념
- RNN Attention
- Today
- Total
클로이의 데이터 여행기
비전공자가 이해한 '마코프 체인(Markov Chain)' 본문
이번 포스팅에서는 자연어 분석의 전통적 모델인 '마코프 체인 모델'에 대해서 설명하고자 합니다.
1. 마코프 체인(Markov Chain)란?
- 통계 기반의 모델로 다음 단어가 나올 확률을 예측하는 방식으로 언어분석 모델로 활용
- 초기의 딥러닝 모델 형태로 네트워크는 확률을 기반함
2. 마코프 체인(Markov Chain) 예시
그렇다면 실제로 마코프 체인을 어떻게 활용하는지 살펴보려고 합니다.
아래와 같은 문장이 있다고 예를 들어봅니다.

[그림 1]처럼 문장들이 있다고 할 때, 하나의 단어를 기준으로 바로 뒤에 어떤 단어가 몇 번 등장하는지 살핍니다.
예를 들어, 'I' 뒤에는 'like'가 2번 등장하였고, 'don't'가 1번 등장하였습니다.
그러면 키워드별로 확률에 기반하여 아래의 [그림 2]을 그려볼 수 있습니다.
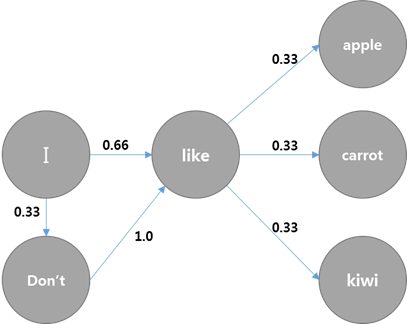
"I" 다음 "like"가 나올 확률은 2/3으로 0.66, "I" 다음 "don't"가 나올 확률은 1/3 0.33이 됩니다.
이를 기반으로 모든 단어의 확률을 아래의 [그림 3]처럼 표현해줍니다.

이렇게 표로 만들게 되면 '특정 키워드 이후 키워드'가 등장하는 확률을 계산할 수 있게 됩니다.
그러면 아래의 [그림 4]처럼 모든 문장의 확률을 구할 수 있게 됩니다.

3. 마코프 체인(Markov Chain) 장단점
장점
- 복잡한 알고리즘 없이 통계기반으로 간단하게 구현 가능
- 통계기반이기 때문에 결과가 나온 이유를 명확히 설명할 수 있음
단점
- 등장하지 않은 패턴에 대해서는 확률이 0 임
- 통계 계산 시, 모든 문장의 경우의 수를 담을 수 없기 때문에 한계점을 극복할 수 없음
이상입니다.
이 포스팅은 Tacademy의 '자연어 언어모델 BERT'를 수강하고 작성되었습니다.
비전공자 관점에서 이해한 만큼만 작성되었으니 부족하더라도 너른 이해 부탁드립니다.
읽어주셔서 감사합니다'◡'
'자연어처리' 카테고리의 다른 글
| 비전공자가 이해한 'Attention' (0) | 2019.12.05 |
|---|---|
| 비전공자가 이해한 'RNN' (0) | 2019.12.02 |

