
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- StringJoiner
- R 워드클라우드
- 딥러닝용어
- 통계기반자연어처리
- 자언어처리모델
- 마르코프 체인
- selfattention
- 상호작용디자인
- RNN Attention
- 마르코프
- deeplearning용어
- wordVector
- deeplearning개념
- 자연어처리
- StringBuffer vs StringBuilder
- R 키워드 가중치
- 도날드노만
- WordCloud R
- 어탠션
- R에서의 워드클라우드
- word2vec
- R dataframe
- HashMap
- 언어모델
- 딥러닝개념
- R에서의 wordcloud
- self-attention
- 체험디자인
- R TF-IDF
- r word2vec
- Today
- Total
클로이의 데이터 여행기
[R] R을 이용한 텍스트마이닝_DataFrame 본문
오늘은 R에서 가장 자주 쓰이는 dataframe을 다뤄보려고 합니다.
R의 가장 큰 장점은 행렬 기반의 데이터를 손쉽게 다룰 수 있다는 점인데요.
이때 가장 자주 또 유용이 쓰이는 데이터 타입이 DataFrame입니다.
1. DataFrame
1) 특징
- 데이터를 행렬로 저장
- 여러가지 데이터 타입을 저장할 수 있음
2) 생성
frame = data.frame(col1 = c(1,2,3), col2 = c("A","B","C"))
▶ 2행 3열의 데이터가 행부터 채워지며 생성됩니다.
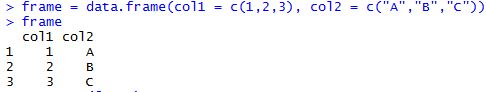
3) 데이터 다루기
(1) 간단한 데이터 조작
① 행/열 이름 확인
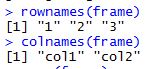
rownames(frame)
▶ 'frame' 데이터의 행 이름(번호)을 확인할 수 있습니다.
colnames(frame)
▶ 'frame' 데이터의 열 이름(컬럼명)을 확인할 수 있습니다.
② 행/열 개수 확인
nrow(frame)
▶ 'frame' 행 개수를 확인할 수 있습니다.
ncol(frame)
▶ 'frame' 열 개수를 확인할 수 있습니다.

③ 행/열 이름 변경
rownames(frame) <- c("a","b","c")
▶ 'frame' 데이터의 행 이름(번호)을 변경할 수 있습니다.
colnames(frame) <- c("no.","fruits")
▶ 'frame' 데이터의 열 이름(컬럼명)을 변경할 수 있습니다.

④ N개 행까지 데이터 확인
head(frame, 2)
▶ 'frame' 데이터를 위쪽부터 2개까지 확인할 수 있습니다.

⑤ dataframe를 matrix로 변경
dfToMat= as.matrix(frame)
▶ dataframe 'frame'이 matrix 형태로 변환됩니다.

(2) Group by 및 Join
① Group by 하기
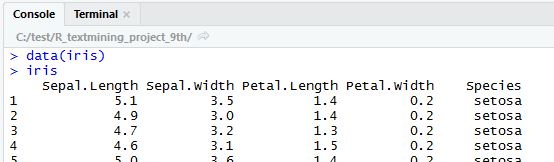
'Group by'는 R에 기본적으로 포함되어 있는 'iris'데이터를 이용해보려고 합니다.
콘솔창에 'data(iris)'를 입력하여 iris 데이터를 불러옵니다.
* 아이리스는 통계학자인 피셔Fisher1 가 소개한 데이터로, 붓꽃의 3가지 종(setosa, versicolor, virginica)에 대해 꽃받침sepal과 꽃잎petal의 길이를 정리한 데이터'라고 합니다. (참고: https://thebook.io/006723/ch04/01/)
tapply(iris$sepal.Length, iris$Width, mean)
tapply(iris$sepal.Length, iris$Width, max)
tapply(iris$sepal.Length, iris$Width, min)
▶ Species별로 sepal.Length의 평균(mean),최대값(max),최소값(min)을 구합니다.

② 데이터 Join 하기
step 1. join 대상 dataframe 준비
fruit_list = data.frame(id=c(1,2,3,4,5,6), name = c("apple","pineapple","kiwi","strawberry","banana","grape"))
origin = data.frame(id=c(2,4,6,8), name = c("seoul","daegu","ulsan","busan"))
▶ 'fruit_list' 에는 id별 과일명이 들어있고, 'origin'에는 id별 원산지가 들어 있습니다.

step 2. Inner Join
가장 이해하기 쉬운 inner join부터 살펴보겠습니다. inner join은 동일한 id가 양쪽(fruit_list,origin)에 있을 때만 join 합니다.
merge (fruit_list,origin, by = "id")
▶ 'fruit_list' 와 'origin'을 'id'를 기준으로 join합니다. 동일한 id가 양쪽(fruit_list,origin)에 있을 때만 join 합니다.

step 3. Left Outer Join
Left Outer Join은 왼쪽 dataframe을 기준으로 join하며 그 값이 없을 시, <NA>로 처리합니다.
merge(fruit_list, origin, by="id", all.x = TRUE)
▶ 'fruit_list' 를 기준으로 join하며, 그 'id'가 'origin'에 없을 시, <NA>로 처리힙니다.

step 4. Right Outer Join
Right Outer Join은 오른쪽 dataframe을 기준으로 join하며 그 값이 없을 시, <NA>로 처리합니다.
merge(fruit_list, origin, by="id", all.y = TRUE)
▶ 'origin' 를 기준으로 join하며, 그 'id'가 'fruit_list'에 없을 시, <NA>로 처리힙니다.

이상입니다. 여기까지 데이터 프레임을 다루는 방법을 살펴보았습니다.
읽어주셔서 감사합니다 : )
'R' 카테고리의 다른 글
| [R] R을 이용한 텍스트마이닝_TF-IDF (코드 및 설명) (0) | 2019.06.20 |
|---|---|
| [R] R을 이용한 텍스트마이닝_Word2vec(코드 및 설명) (3) | 2019.05.31 |
| [R] R을 이용한 텍스트마이닝_'stringr' package (0) | 2019.04.19 |
| [R] R을 이용한 텍스트마이닝_vector,list,matrix (0) | 2019.04.09 |
| [R] R을 이용한 텍스트마이닝_prologue (0) | 2019.03.19 |



